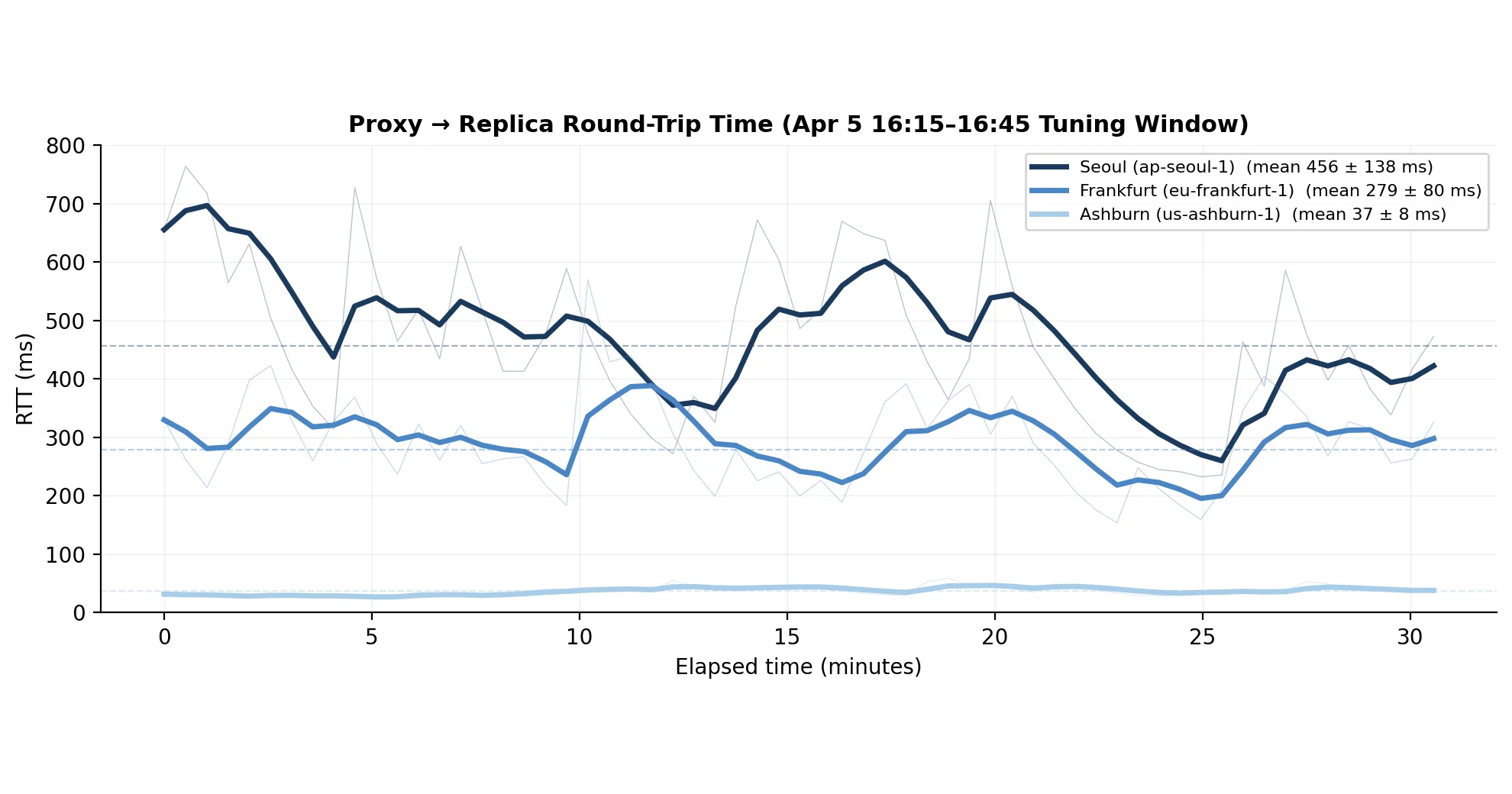
A request sent over the internet from a server in Ashburn takes, on average, ~279 ms to reach a replica in Frankfurt and get an answer back; to Seoul, ~456 ms. That's a 12× spread over the ~37 ms round-trip to a local replica, widening to ~23× at Seoul's peak. When you're serving LLM inference from replicas in multiple regions, that network round-trip is embedded in every request's latency—and almost no production routing policy accounts for it.
We built GORGO to fix that. It’s a CPU proxy that routes LLM inference requests across a multi-region fleet, with an online tuning method that learns its routing cost weights from the deployment’s own latency stream—no modifications to the inference engine required. The full method and results are in the paper.
The user-perceived latency for an LLM is dominated by time-to-first-token (TTFT)—the gap between submitting a prompt and seeing the first generated word. Once the model starts producing tokens, decode latency (time per subsequent token) matters less than people expect; the initial stall is what makes inference feel slow.
On a single replica, TTFT is dominated by three costs: prefill time (the GPU work of computing the key-value (KV) cache for the prompt tokens), the round-trip time (RTT) from the proxy to the replica, and queueing delay behind requests already in flight. Modern inference engines like SGLang implement prefix caching (RadixAttention): if a previous request already computed the KV cache for your system prompt, the engine skips recomputing those tokens entirely. This makes cache hit rate a first-class routing concern—route to a replica that already has your prefix and you pay no prefill cost for those tokens.
Standard routing policies try to exploit this in different ways. Consistent hashing and session affinity stick requests to replicas that have seen similar prompts before. Longest-prefix-match routing (as implemented in AIBrix) actively computes how much of each request’s prefix is already cached on each replica and routes to the best match. Load-based policies—least-request, least-load—ignore caches and just spread work evenly.
None of them account for wide-area network latency. In a single-region deployment, RTT is a millisecond and safely ignorable. In a cross-region fleet, RTT is a 37–456 ms overhead on every single request. Routing to Frankfurt because it has a cache hit, when Ashburn is 240 ms closer and already has the same prefix cached, can be wrong—and none of the standard policies have any term in their cost model to notice.
GORGO is a single routing policy that puts KV-cache locality, replica load, and wide-area network latency into one cost function, with weights derived from the deployment’s own per-request TTFT stream.
The router maintains three data structures: a radix trie of which prefixes are cached on which replica (inferred from the router’s own routing history), a live proxy-side counter of queued tokens per replica (not queried from the engine—counted locally), and an EWMA (exponential weighted moving average) of ping RTT to each replica. On each incoming request, it scores every candidate replica:
where uncached_tokens = input token count minus the prefix already cached on that replica. Route to whichever replica minimizes the score.
The proxy-side cache trie is approximate. It tracks what the router has sent where, not what the engine actually has in memory—evictions and prefill failures aren’t directly observed. That’s acceptable: the alternative, querying each replica’s cache state per-request, would add its own latency overhead on the path it's trying to shorten.
Two scalar weights—rtt_weight and queue_weight—control how much network latency and queueing pressure each factor into the routing decision. We built two variants for setting them.
gorgo-static fixes the weights for the entire run. Not the interesting variant—it tests whether the cost model’s structure carries value at all, independent of any tuning.
gorgo-hillclimb runs a (1+1) evolution strategy with Rechenberg’s 1/5 success rule, searching the dimensionless weights in log-space to directly minimize p95 TTFT over a rolling 64-request window. At each step: propose a Gaussian-perturbed candidate; accept it if it beats the incumbent on the current window; widen the step size if more than 20% of recent proposals succeed, narrow it if fewer. No gradient, no look-ahead, no model of the objective function—just a self-correcting local search that adapts to the noise level of the signal.
The search space is two-dimensional. The objective is noisy. Evolution strategies are well-matched to that regime; they’re robust to non-convexity and require no differentiability.
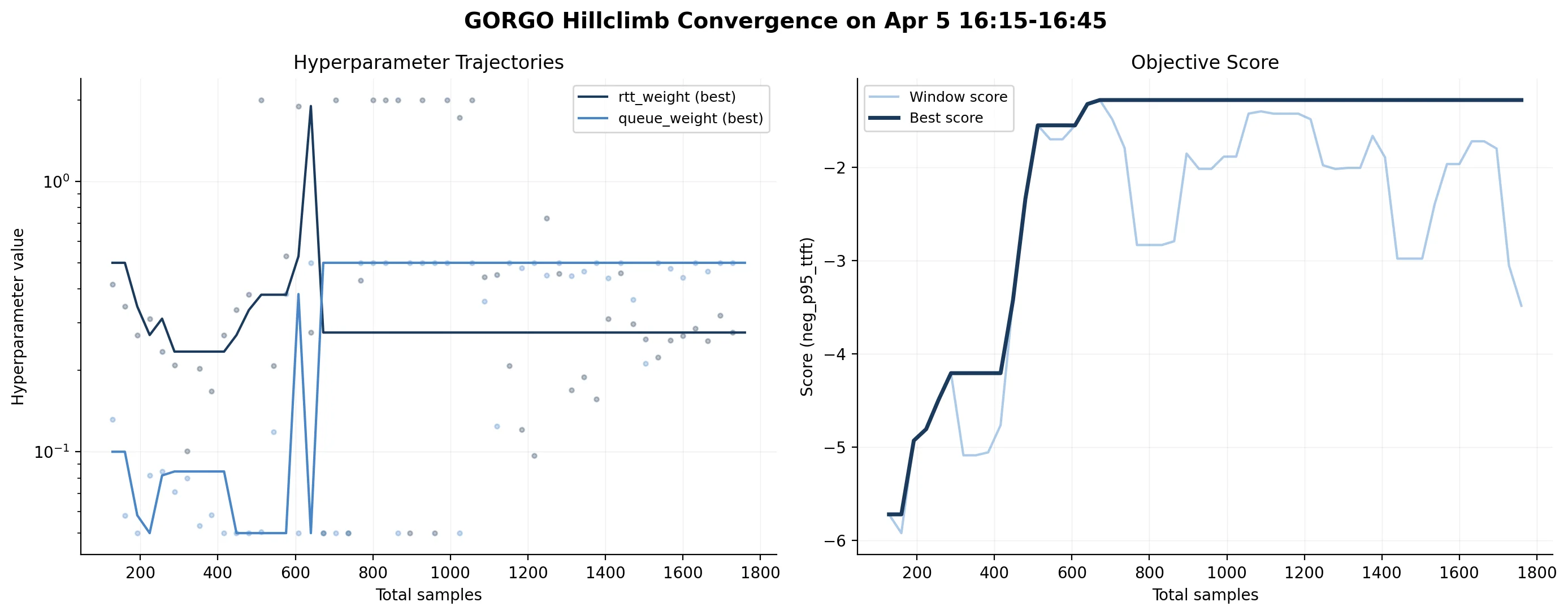
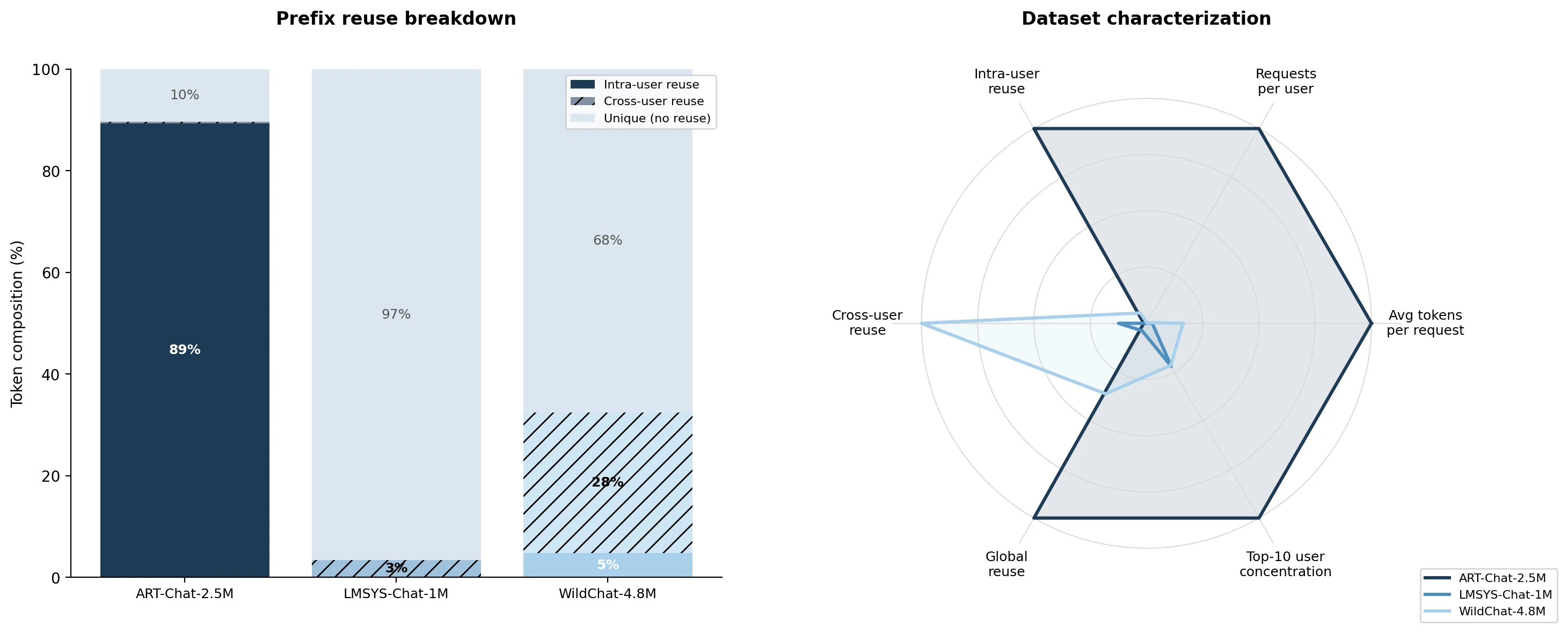
rtt_weight to ~0.28, queue_weight to 0.5. Right: the objective (negative p95 TTFT) climbs and plateaus as the accepted-step rate falls toward the 1/5 target. These become the frozen weights carried into evaluation. (Figure from the paper.)The existing benchmarks for LLM serving are short-prompt, and what reuse they have is the wrong kind. LMSYS-Chat-1M averages ~467 input tokens with ~3% prefix reuse. WildChat-4.8M averages ~2,925 tokens with ~33% reuse—but almost all of that is cross-user, shared system-prompt templates rather than reuse within a single conversation. If prompts are short and the only common prefix is a boilerplate header, there’s little routing locality to exploit.
Real long-context production traffic is different. We built ART-Chat-2.5M from long-context production metadata: ~2.5M requests from ~5K users, averaging ~18,000 input tokens—~38× longer than LMSYS, ~6× longer than WildChat—with ~90% prefix reuse, almost all of it within a single user’s own multi-turn session. The metadata source is production traffic from a GLM-family model endpoint; the served model in our experiments is Qwen3.5-35B-A3B-FP8, a mixture-of-experts model with 35B total and ~3B active parameters. ART-Chat-2.5M is the regime where prefix caching and cross-region routing actually interact—the one public datasets don’t cover. (Dataset and router are open source: code, data.)
Experimental setup: three regions (Seoul, Frankfurt, Ashburn), each running a single 2×L40S SGLang server on Modal, isolated per policy so caches can’t cross-contaminate across conditions. Concurrency up to 64. Baselines: random, least-request, least-load, prefix-cache via AIBrix, and simple-session-affinity.
The evaluation protocol matters: tune the weights on a window of requests, freeze them, then evaluate on a held-out window.
Over held-out windows, GORGO improves p95 TTFT by 8–15% and end-to-end (E2E) latency by 15–31% over the strongest baselines (session affinity and prefix-cache). On one held-out window: p95 TTFT improved 15.5% (1,584 ms vs. 1,875 ms) and E2E p95 improved 30.8% (3.29 s vs. 4.75 s). On a saturated in-sample window: E2E p95 fell 34.9% (8.91 s vs. 13.69 s) while trailing session-affinity by only 3.5% on TTFT p95.
| Policy | TTFT p50 | TTFT p95 | TTFT p99 | E2E p95 |
|---|---|---|---|---|
| Tuning window · Apr 5, full load · in-sample | ||||
| GORGO | 673 | 2,514 | 4,473 | 8.91 |
| simple-session-affinity | 712 | 2,428 | 5,190 | 18.27 |
| least-load | 763 | 2,447 | 4,349 | 13.69 |
| least-request | 968 | 3,970 | 7,012 | 16.62 |
| prefix-cache | 1,477 | 6,784 | 9,613 | 22.63 |
| Held-out · Apr 6, half load | ||||
| GORGO | 491 | 1,584 | 2,222 | 3.29 |
| simple-session-affinity | 627 | 1,875 | 3,056 | 4.75 |
| least-load | 616 | 1,818 | 2,885 | 4.06 |
| least-request | 634 | 1,852 | 2,484 | 3.99 |
| prefix-cache | 574 | 1,798 | 2,750 | 4.95 |
| Held-out · Apr 7, third load | ||||
| GORGO | 386 | 1,377 | 1,973 | 3.34 |
| simple-session-affinity | 439 | 1,495 | 2,313 | 3.90 |
| least-load | 480 | 1,637 | 2,294 | 4.04 |
| least-request | 509 | 1,724 | 2,485 | 4.40 |
| prefix-cache | 516 | 1,830 | 2,801 | 11.98 |
rtt_weight 0.276, queue_weight 0.5), learned by (1+1)-ES on the Apr 5 window and frozen for both held-out windows. Bold is best in column within each window; lower is better throughout. TTFT in ms, E2E p95 in s. On both held-out days GORGO sweeps every metric.We were surprised to discover what happens when gorgo-hillclimb optimizes a TTFT-only objective with unconstrained weight ranges.
It doesn’t learn good routing. It learns that it can drive measured p95 TTFT down by routing nearly 100% of traffic to the single nearest replica and zeroing out the load weight. The metric looks excellent. Everything else collapses.
The mechanism: TTFT doesn’t price queueing or decode contention until a replica saturates. An overloaded replica still returns its first token quickly—the request lands in the KV cache and generation begins—so the proxy’s reward signal looks fine while end-to-end latency quietly blows up. The optimizer found that concentrating load minimizes TTFT without any penalty visible to the objective it was given.
The ablation is clean. Load weight zeroed out: TTFT p95 was 1.101 s, E2E p95 was 12.58 s, load concentration ~100% on one replica. Load weight restored: TTFT p95 was 1.136 s, E2E p95 was 2.46 s, concentration ~60%. That’s a ~3% regression on TTFT for a ~5× improvement on E2E. It’s not a close call.
The fix is structural: floor the load weight so the optimizer can’t zero it out, cap the RTT weight so it can’t route purely by geography. And freeze the tuned weights for production rather than running the optimizer live. Live tuning produces heavy-tailed latency excursions mid-production as the hillclimber explores the weight space—freezing isn’t just a convenience, it’s a safety property.
The general pattern is reward hacking: let an optimizer loose on a proxy metric and it optimizes the proxy. TTFT was the proxy. What users feel is end-to-end latency. The gap between those two wasn't obvious until the hillclimber found it—and it found it immediately.
On WildChat, GORGO is not competitive. The gorgo variants lose to session affinity on p95 TTFT in those experiments—gorgo-static is the worst, at ~1.93 s vs. ~1.03 s for plain session affinity. Short prompts, low reuse: there's little cache locality to route toward, and the extra machinery adds noise rather than signal. The method's value is conditional on long contexts and high prefix reuse—deploy it on short-prompt, low-reuse traffic and you should expect it to lose to a policy with less to get wrong.
Per-window tuning is also noisy in ways that matter. Re-evaluating identical weights across windows produced swings large enough that some apparent optima were noise artifacts that generalized poorly to held-out data. This is part of why frozen weights on held-out windows are the right evaluation criterion—in-sample performance overstates what you actually get.
The results come from a single-tenant fleet of identical GPUs, with no prefill/decode disaggregation and metrics observed only over HTTP. P99 differences sit at the edge of statistical significance given the sample sizes.
Prefill/decode disaggregation—serving prompt-processing and token-generation on separate hardware—may dissolve much of the TTFT-vs-E2E tension that drove the reward hack: with a dedicated prefill cluster, TTFT would be governed by prefill scheduling rather than by a generation replica's queue depth, which is exactly the coupling the optimizer exploited. That's a hypothesis for follow-on work, not a result.
The router's job is to price what the user feels. The moment you let it optimize a cheaper stand-in, it will—and it will find corners you didn't anticipate. The useful thing about gorgo-hillclimb isn't that it finds good weights; it's that, unconstrained, it goes straight for the degenerate solution, and the degenerate solution is the cleanest proof that TTFT and end-to-end latency are different objectives that happen to agree until a replica saturates.
Pricing the network alongside cache locality and load is the easy half. The hard half is that the weights worth having can be learned from the deployment's own traffic—but only once you've stopped the optimizer from gaming the metric you gave it.